In this article I will introduce some of the tools used to model volatility with examples in Matlab. Let’s start with a definition of volatility –
Volatility is the degree of variation of a price series over time as measured by the standard deviation of returns.
Why is volatility of vast importance in financial world? One of the main reason is because it’s used as a measure of risk. Greater volatility of an asset means riskier opportunity for potential investor and vice versa. In practice traders can use output from volatility models to set up leverage(or any other parameter) of their positions thus volatility can help optimize a trading strategy. Usually PnL of a trading strategy is a function of volatility or at least variance of PnL is. We can explore such a volatility-PnL relation via regression analysis but it’s not aim of this article.
Historical volatility
Sometimes called realized volatility or simple moving average(SMA). The historically oldest approach to volatility comes directly from the definition. We just select rolling window of length  over time serie and calculate volatility as sample variance of returns over given period from time
over time serie and calculate volatility as sample variance of returns over given period from time  to
to  . That is
. That is
(1) 
where  is simply sample mean of returns over given period calculated over same window from to
is simply sample mean of returns over given period calculated over same window from to
![\[ \hat{\mu}_t = \frac{1}{k}\sum \limit _{\tiny \tau=t-k}^{\tiny t-1}r_\tau \]](http://mmquant.net/wp-content/ql-cache/quicklatex.com-d247d6b06d5bff9685716b2da56ee139_l3.png "Rendered by QuickLaTeX.com")
and  is particular asset return over one time unit
is particular asset return over one time unit
![\[ r_\tau = ln \bigg(\frac{p_{\tau}}{p_{\tau-1}}\bigg)\hspace{5pt}. \]](http://mmquant.net/wp-content/ql-cache/quicklatex.com-689c7871bfc100be6138bb6d394d3681_l3.png "Rendered by QuickLaTeX.com")
Observe that this model has one big disadvantage of assigning equal weights to terms in sum in (1). Suppose there was some short-term significant swing in volatility at time  . Then every calculation of
. Then every calculation of  from time to time
from time to time  will contain this outlier with same weight. This will cause plateauing of such an estimate. Download function for calculation here. I will demonstrate the plateauing effect on bitcoin daily price time serie.
will contain this outlier with same weight. This will cause plateauing of such an estimate. Download function for calculation here. I will demonstrate the plateauing effect on bitcoin daily price time serie.
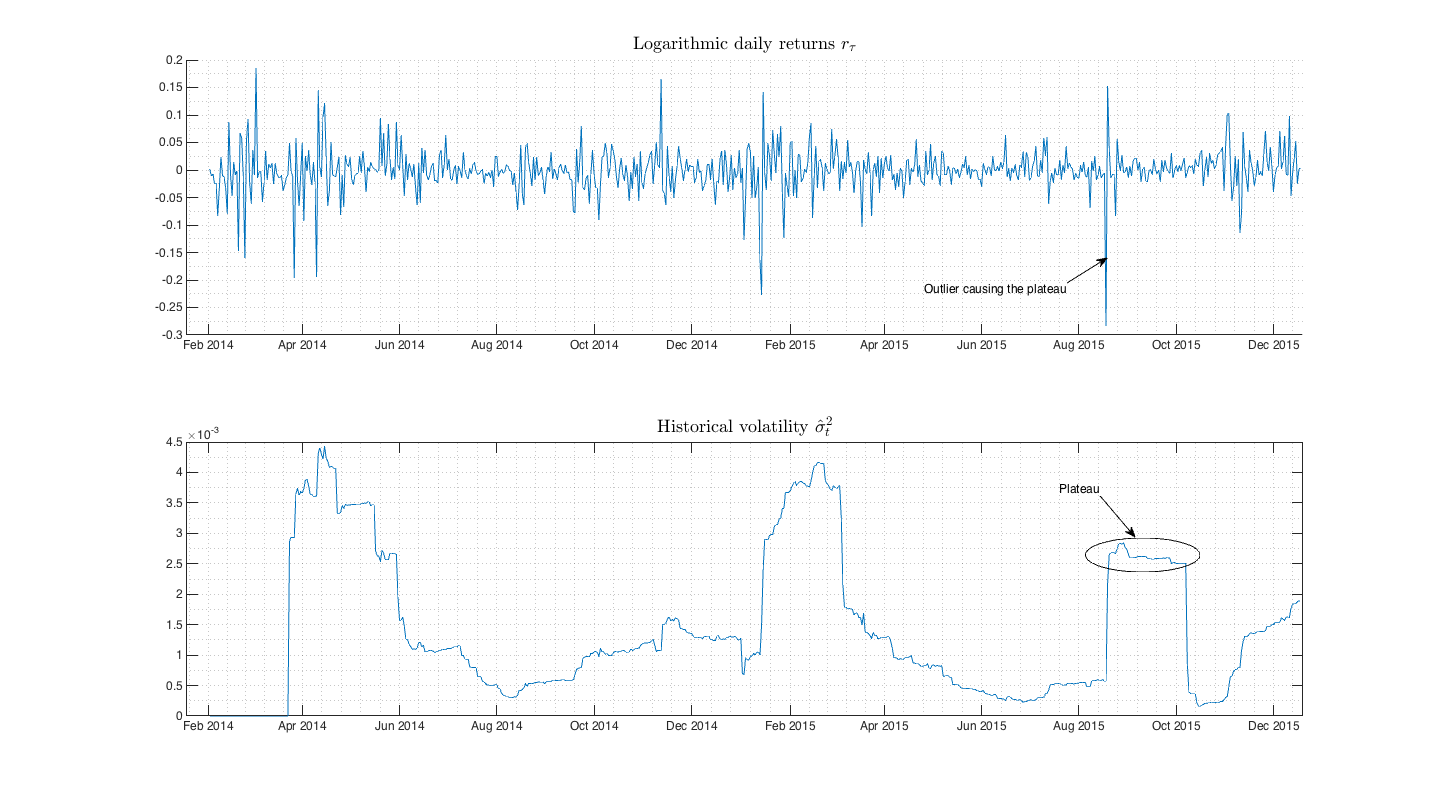 Fig.1 On these two plots we can see that sudden fluctuation of returns causes the plateauing effect and the model gives strongly biased volatility estimate.
Fig.1 On these two plots we can see that sudden fluctuation of returns causes the plateauing effect and the model gives strongly biased volatility estimate.
The market convention is to quote in terms of annualized volatility. For daily historical volatility we have  and we can annualize it as
and we can annualize it as  .
.
If we slightly modify the (1) considering  we get rid of one estimation. This can be clearly done just for series of logarithmic returns, not for price series. Thus we get simple close-close volatility estimator
we get rid of one estimation. This can be clearly done just for series of logarithmic returns, not for price series. Thus we get simple close-close volatility estimator
![\[ \hat{\sigma}_t^2 = \frac{1}{k-1}\sum \limit _{\tiny \tau=t-k}^{\tiny t-1}r_\tau^2 \hspace{5pt}. \]](http://mmquant.net/wp-content/ql-cache/quicklatex.com-3587b9c88357479470216ed919e3d5f4_l3.png "Rendered by QuickLaTeX.com")
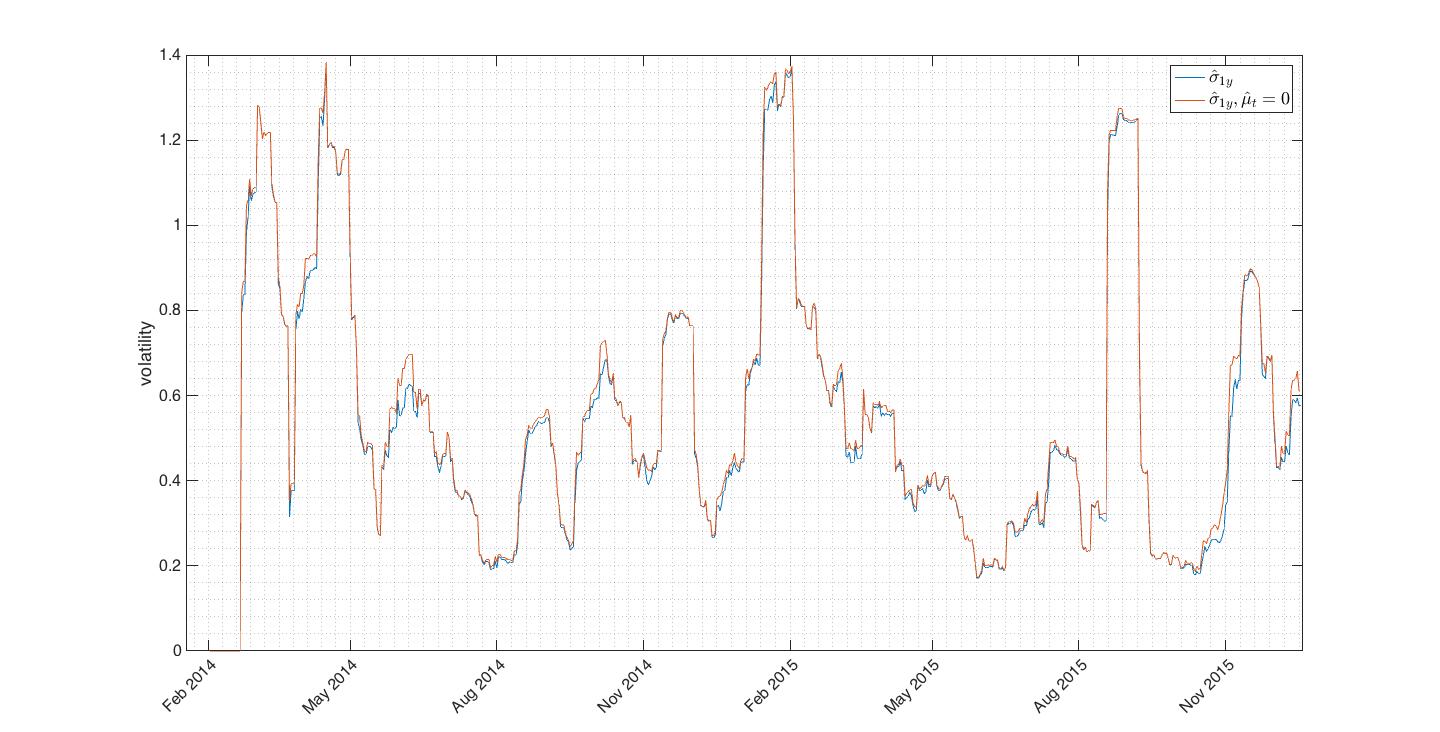
Fig.2 Comparison of SMA and SMA with close-close approach. Both estimates follows tightly each other.
EWMA model
EWMA model is extented version of forementioned simple historical volatility and partial solution to the plateauing issue. EWMA approach was developed by J.P.Morgan within the RiskMetrics methodology framework and is defined as follows
(2) 
or after rearranging
(3) 
where  is an asset price,
is an asset price,  is mean of an asset price and
is mean of an asset price and  is decay factor such that
is decay factor such that  . In (2) note that as
. In (2) note that as  we have
we have  or
or  so deeper observations get smaller and smaller weights.
so deeper observations get smaller and smaller weights.
If we want EWMA model for logarithmic returns we just swap in (2) and (3) for  and in practice we can drop the
and in practice we can drop the  term after we checked that
term after we checked that  holds. Hence we get
holds. Hence we get
![\[ \hat{\sigma}_t^2 = (1-\lambda )r_{t-1}^2 + \lambda \hat{\sigma}_{t-1}^2 \hspace{5pt}. \]](http://mmquant.net/wp-content/ql-cache/quicklatex.com-f4aa16b1a168863bf754170cf56487b9_l3.png "Rendered by QuickLaTeX.com")
Observe how  and weight terms in the model. Greater makes model more affected by last variance, in other words model tends to revert to its previous volatility level(variance). Conversely small gives more weight to last return. is sometimes called memory because it directly affects how much is variance dependent on its previous value. RiskMetrics methodology suggest use
and weight terms in the model. Greater makes model more affected by last variance, in other words model tends to revert to its previous volatility level(variance). Conversely small gives more weight to last return. is sometimes called memory because it directly affects how much is variance dependent on its previous value. RiskMetrics methodology suggest use  which is widely used by practitioners.
which is widely used by practitioners.
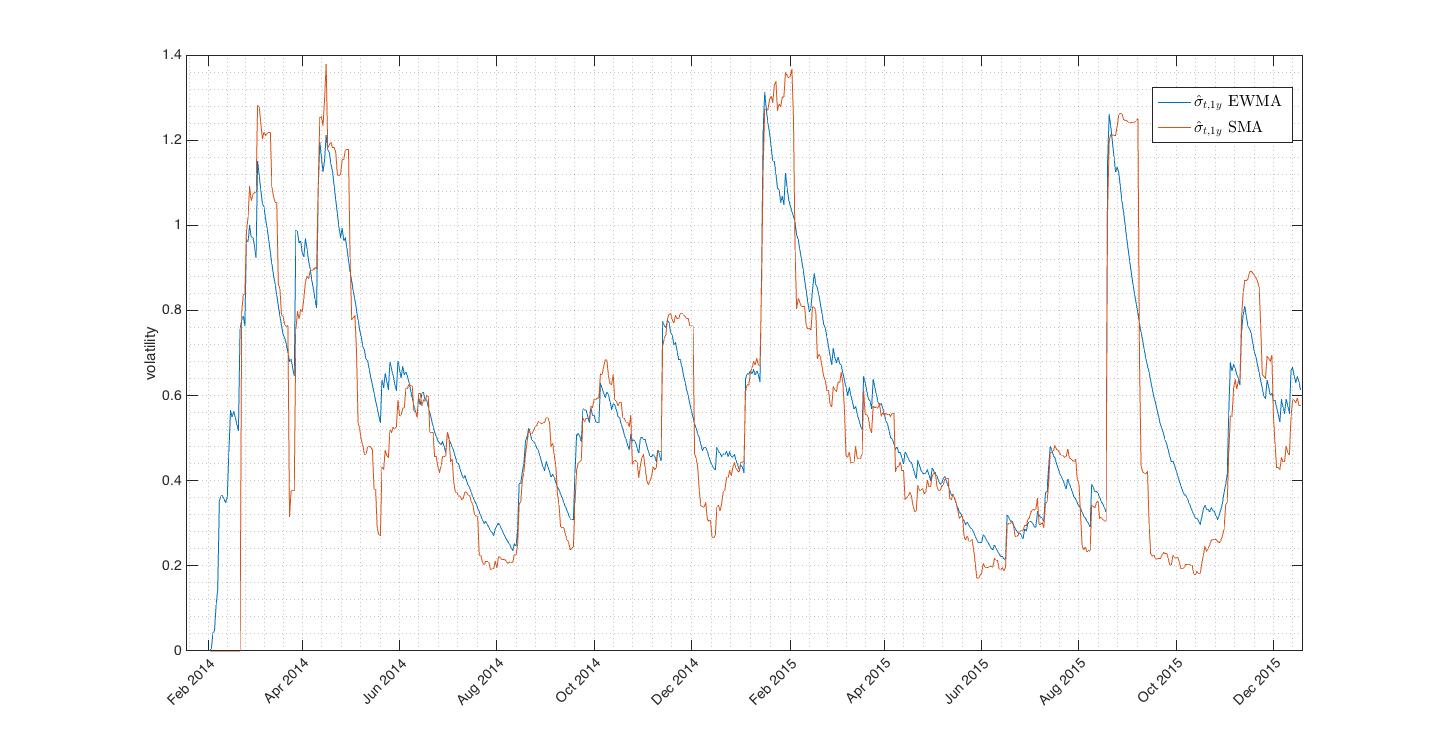 Fig.3 Exponentially decaying EWMA is still biased by outliers but gives much better volatility estimate than SMA.
Fig.3 Exponentially decaying EWMA is still biased by outliers but gives much better volatility estimate than SMA.
You can download Matlab function for EWMA volatility estimate here.
Parkinson estimator
In 1980, a physicist Michael Parkinson showed in his paper that we can project additional information to volatility estimate by using not just close prices but rather price extremes. He proposes use of log differences between highs and lows over specified time window. Such an estimator is five times more efficient than historical SMA approach (for same amount of input data PE variance is 1/5th of SMA variance). Rolling PE is given by
![\[ \hat\sigma_t^2 = \frac{1}{4\>k\>ln(2)} \sum \limit _{\tiny \tau=t-k}^{\tiny t-1} ln^2 \left( \frac{H_\tau}{L_\tau}\right) \]](http://mmquant.net/wp-content/ql-cache/quicklatex.com-71d38f8fcb9aaab5e93d32b338f9a4d7_l3.png "Rendered by QuickLaTeX.com")
where  is PE volatility computed over given time window to and
is PE volatility computed over given time window to and  are corresponding high and low.
are corresponding high and low.
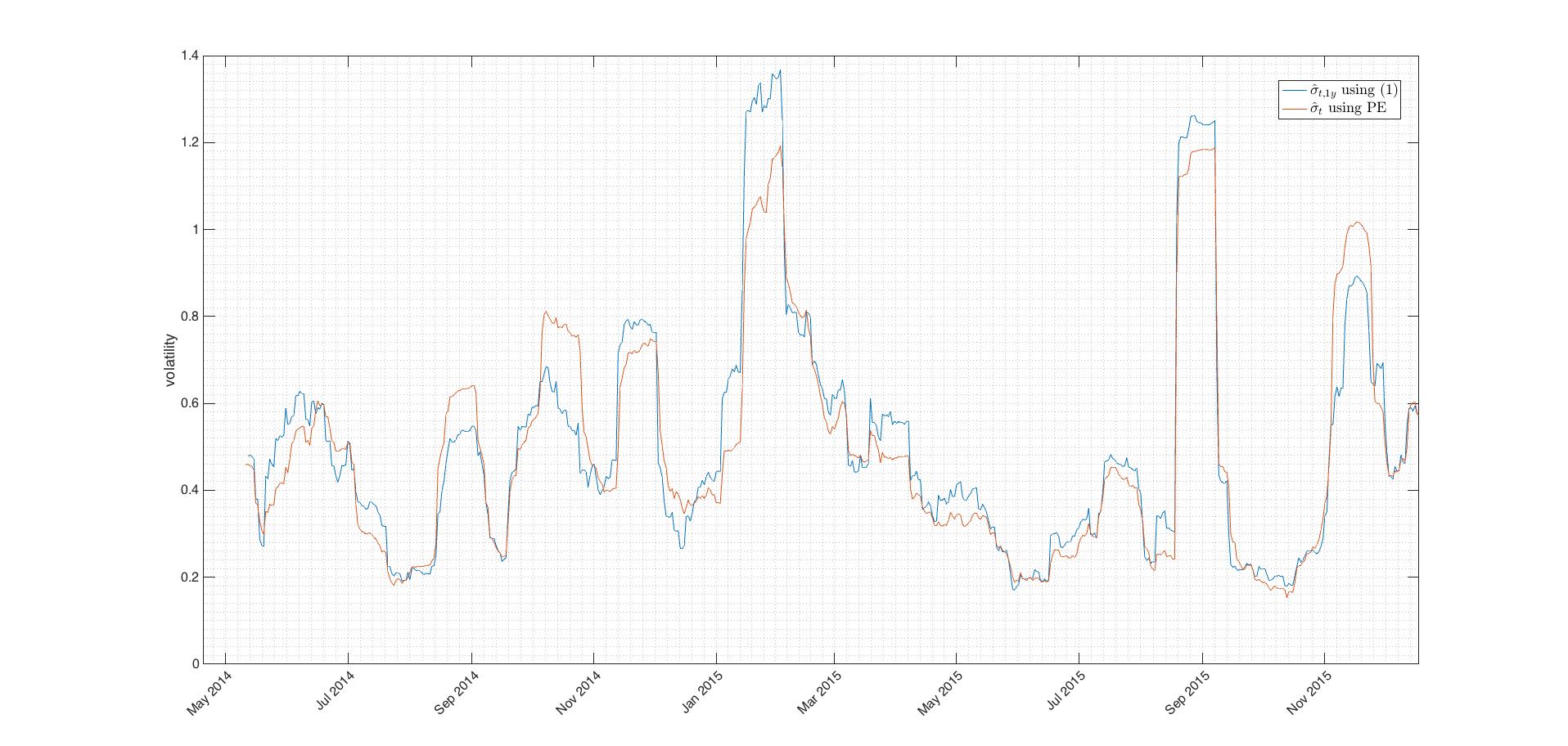
Fig.4 Even that Parkinson estimator is significantly more precise in the term of variance it tends to underestimate volatility as seen on picture above. It should be used in combination with other estimators which don’t underestimate. We can include PE in a volatility composite.
Plots above were made using my PEvol() function.
Garman-Klass estimator
In 1980, Garman-Klass realized that utilizing all of the OHLC information must give even more precise volatility estimation than PE. It can be explained as an optimal (smallest variance) combination of SMA and PE. G-K estimator is 7.4x more efficient than SMA. Considering our rolling window of size , G-K estimator is written as
(4) ![\begin{equation*} \hat\sigma_t^2 = \frac{1}{k} \sum \limit _{\tiny \tau=t-k}^{\tiny t-1}\Big[0.511\hspace{2pt} ln^2\Big(\frac{H_{\tau}}{L_\tau}\Big) - 0.019\hspace{2pt} ln\Big(\frac{C_\tau}{O_\tau}\Big)\>ln\Big(\frac{H_\tau L_\tau}{O^2_\tau}\Big) - 2\hspace{2pt}ln\Big(\frac{H_\tau}{O_\tau}\Big)\>ln\Big(\frac{L_\tau}{O_\tau}\Big)\Big] \end{equation*}](http://mmquant.net/wp-content/ql-cache/quicklatex.com-94e9e221688b6774284c09cdcc5fea00_l3.png "Rendered by QuickLaTeX.com")
where  are respectively open,high,low,close at time
are respectively open,high,low,close at time  in the particular rolling window. Second term in (4) in the brackets can be neglected since it’s very small.
in the particular rolling window. Second term in (4) in the brackets can be neglected since it’s very small.
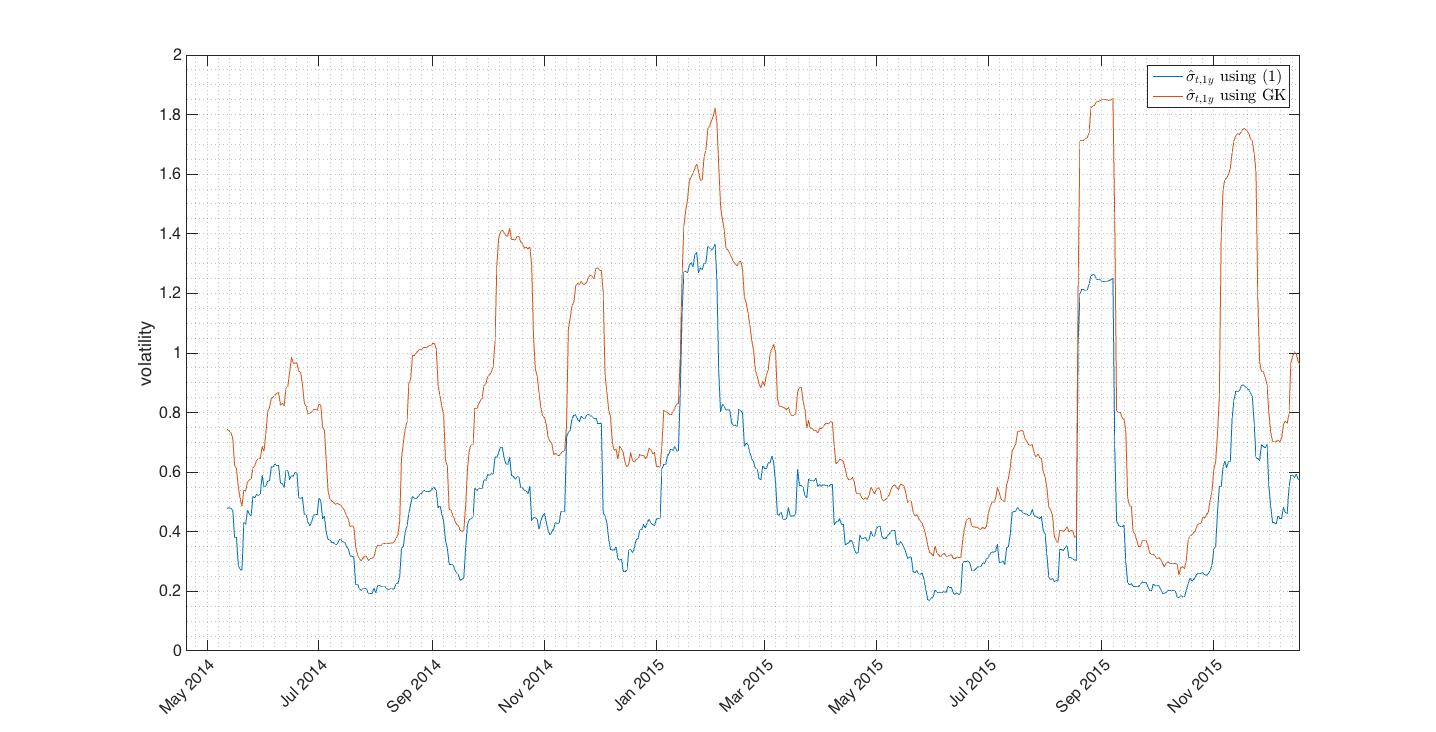
Fig.5 Disadvantage of G-K estimator is that it’s trend dependent. As we used bitcoin price data with strong drift the G-K estimation gives overestimated volatility values.
Download Matlab function for Garman-Klass estimation.
Rogers – Satchell
R-S volatility estimator was published in 1991. This estimator is independent of the drift and computed as
(5) ![\begin{equation*} \hat\sigma_t^2 = \frac{1}{k} \sum \limit _{\tiny \tau=t-k}^{\tiny t-1}\Big[ln\Big(\frac{H_{\tau}}{C_\tau}\Big)\>ln\Big(\frac{H_{\tau}}{O_\tau}\Big) + ln\Big(\frac{L_{\tau}}{C_\tau}\Big)\>ln\Big(\frac{L_{\tau}}{O_\tau}\Big)\Big] \hspace{5pt}. \end{equation*}](http://mmquant.net/wp-content/ql-cache/quicklatex.com-6851c73ee0746a0a5d10c2303025f9f2_l3.png "Rendered by QuickLaTeX.com")
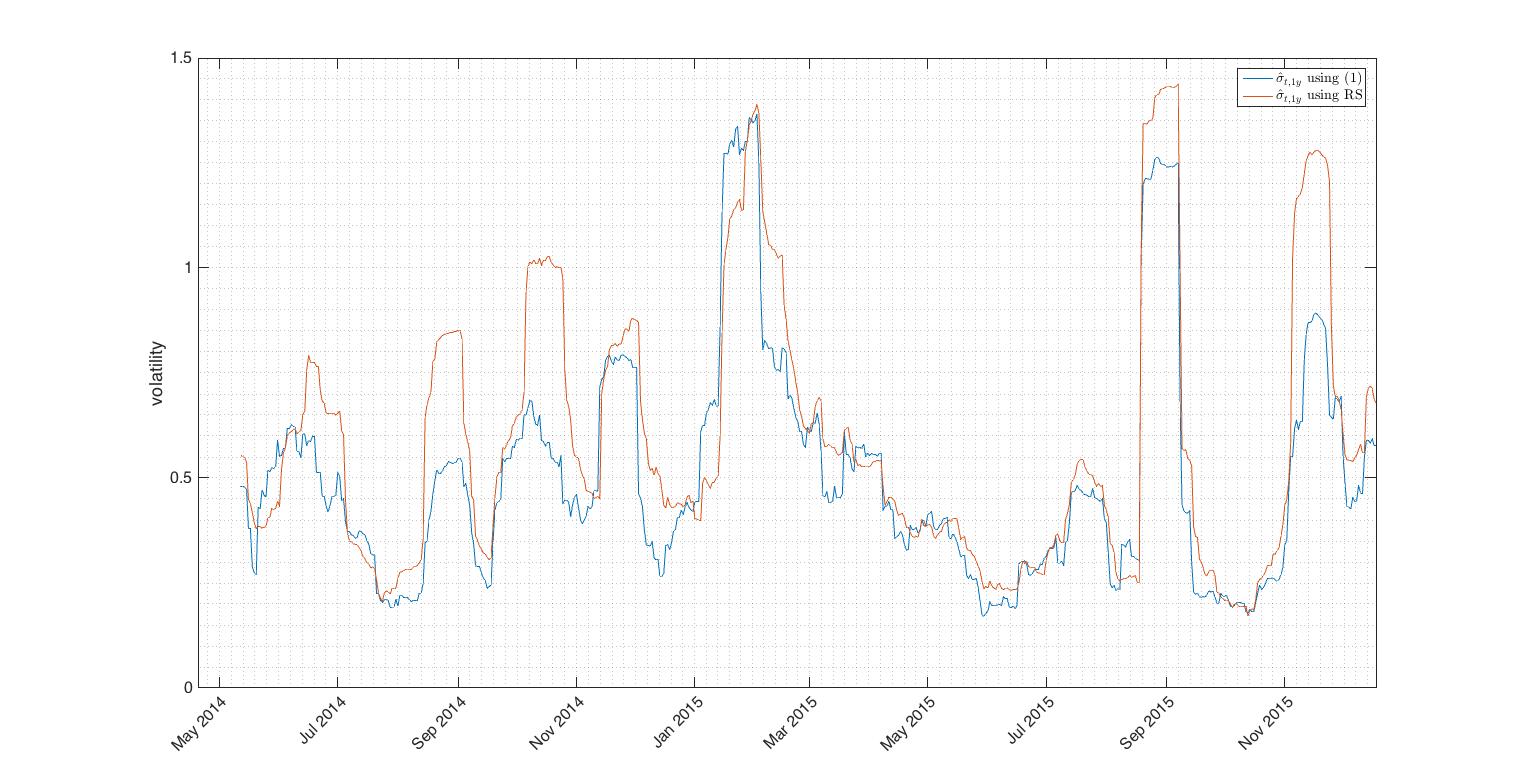
Fig.6 R-S estimator closely follows SMA estimate during low volatility periods. Difference of estimators during volatility peaks is due to the wide trading ranges in these periods and lack of SMA estimator incorporate this fact.
Matlab function for R-S estimate can be downloaded here.
Discussion above shows that historical volatility estimators can be sorted into
- mean-deviation estimators (SMA, EWMA)
- close-close estimators (SMA(), EWMA())
- range estimators (P-E, G-K, R-S).
Great paper on properties of range-based estimators with further details can be downloaded here.