This post will guide you through building up the database solution for market data from scratch. Database will daily update itself with data directly from CME. I will use R6 Parser class as interface between the database and CME settlement files. As a database I utilize PostgreSQL(PSQL) as it’s pretty fast, free, features rich, has clear documentation and is based on standard widespread SQLanguage. That was fast intro so let’s start putting pieces together.
Notice
This parser is intended to be an educational project. Use of CME settlement files for any other purposes without CME permission is forbidden. If you want to use this project in serious real world application you have to use other source of daily prices or contact CME about your intentions. Note that in practice analysts have prices coming from multiple data vendors so they can cross-check their accuracy.
PostgreSQL installation
I’m using Debian on my workstation so this walktrough deals with PSQL installation on Debian (or Debian based) machine. Even if you will install PSQL on different OS, have a quick look at the user and database name I will be using. Remember that there exist front-end clients for PSQL such as web-based phpPgAdmin or standalone pgadmin which you can use for better overview over your databases. Anyway if you are not familiar with the SQL I recommend you to glance over some short tutorial.
Fire up console, get and install PSQL server and client. Installation needs root privileges.
$ sudo apt-get install postgresql postgresql-client
Installation created new system user postgres. This is superuser for all PSQL related administration. Switch to the postgres user and start the PSQL command line tool psql. Default password for postgres user is “postgres”.
$ sudo -u postgres bash $ psql
In psql command line change postgres default password.
=> \password postgres
2x Ctrl-d switches you back to the bash console. Create new system user r_client. This is the user for our later R tool. Provide just password and leave other fields blank.
$ sudo adduser r_client
Create new database user.
$ sudo -u postgres createuser r_client
Create new database.
$ sudo -u postgres createdb -O r_client cme_data
Note that system user name and database user name are the same. If you want use different system/db names you need configure pg_ident.conf file and define custom system/db name maps.
Interfacing database with R
Because I want to access the database from remote machine I need to configure PostgreSQL server to allow remote connections. If you are using PSQL server and PSQL clients (R, pgAdmin) on same machine I recommend you to do following configuration as well because I noted that PSQL server doesn’t listen on defined port by default.
Locate and edit pg_hba.conf file.
$ locate pg_hba.conf /etc/postgresql/9.4/main/pg_hba.conf . $ sudo -u postgres nano /etc/postgresql/9.4/main/pg_hba.conf
Append following line(change IP and subnet according to yours):

Enable database listening on all local interfaces and default port 5432.
$ locate postgresql.conf /etc/postgresql/9.4/main/postgresql.conf . $ sudo -u postgres nano /etc/postgresql/9.4/main/postgresql.conf
Find and set following directives:
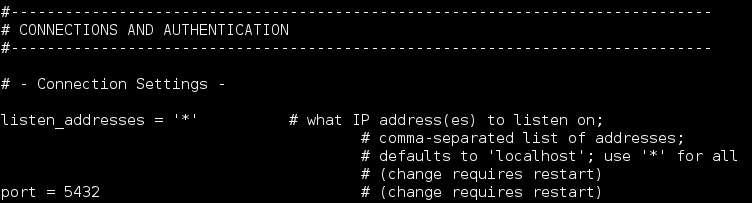
Restart server.
$ sudo service postgresql restart
Install and load CRAN packages (I’m using RStudio IDE).
> install.packages("RPostgreSQL", "data.table", "DBI", "R6", "stringr")
> library("RPostgreSQL")
> library("data.table")
> library("DBI")
> library("R6")
> library("stringr")
So now we have PSQL database server running and properly configured for remote connections. Setting up the R was quite straightforward.
Database design
Now with database ready we need to work out how the data scheme will actually look like. What is the structure of tables and what are relations between them. Let’s work with following simple design.
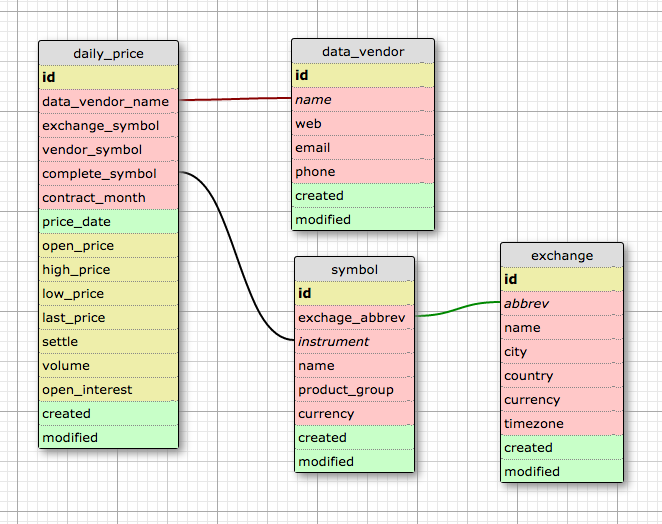
My cme_data database consists of four tables – daily price, data_vendor, symbol, exchange. Have a look at particular columns description. Note that I’m using table:column_name notation and that not all columns are described considering their names as self-explanatory.
daily_price
- id – Serial number as primary key. (example: 1, 2, 3, 4, …)
- data_vendor_name – Data vendor name with foreign key data_vendor:name. (example: IB, GLOBEX)
- exchange_symbol – Instrument symbol as denoted by exchange with foreign key symbol:instrument. (example: AC)
- vendor_symbol – Instrument symbol as denoted by data vendor. (example: EH)
- complete_symbol – Instrument symbol with contract month and year identifier. (example: EHJ13)
- contract_month – Contract month of the given instrument in form MMMYY. (example: APR13)
symbol
- name – Full name of the instrument. (example: ETHANOL)
- product_group – Sector which does the instrument belong to. (example: Energy)
- currency – Currency which is the instrument traded in.
Such design allows symbol table for multiple OHLCV data with same date and instrument but different data vendors.
Before we start using R, clone cme_parser repository from my github and change R working directory via setwd() function to cme_parser directory. I will use sql files as input to R functions and scripts. Customize and run following R script. It creates desired tables and function triggers which automatically updates time in modified column.
### Connection
library(DBI)
library(RPostgreSQL)
drv <- dbDriver("PostgreSQL")
# con <- dbConnect(drv) # default connection for localhost
con <- dbConnect(drv,
dbname = "cme_data",
host = "192.168.88.202", # use PSQL server IP or "localhost"
port = 5432,
user = "r_client",
password = "yourPassword")
## Create tables
fileName <- "DBqueries/create_tables.sql"
query <- readChar(fileName, file.info(fileName)$size)
dbExecute(con, query)
## Create function trigger
fileName <- "DBqueries/update_trigger.sql"
query <- readChar(fileName, file.info(fileName)$size)
dbExecute(con, query)
## Check created tables and field names
tables <- dbListTables(con)
for (i in 1:length(tables)) {
cat(dbListFields(con, tables[i]))
cat("\n-----------------------------------------------------------------------------\n")
}
# Disconnect from database
dbDisconnect(con)
Populating database
With tables ready we can start populating them. First we fill tables containing foreign keys for other tables. We can’t fill daily_price or symbol table first because some of their columns are related to other tables in other words if we want to insert data into constrained column in daily_price, PSQL will try to match our input data with data in “foreign key” table symbol which is obviously empty so it will cause error. Make sure your con connection object is still active and run following code.
### Populating data_vendor table fileName <- "DBqueries/populate_data_vendor_table.sql" query <- readChar(fileName, file.info(fileName)$size) dbExecute(con, query) ### Populating exchange table fileName <- "DBqueries/populate_exchange_table.sql" query <- readChar(fileName, file.info(fileName)$size) dbExecute(con, query)
The symbol table is little bit trickier to fill. Well, as you know the instrument full symbol consists of three parts – exchange symbol, contract month and contract year. So for example for March 2017 US T-Bonds we have complete symbol ZB H 17 (spaces added just for clearness). For current database purposes I chose 54 instruments from various markets. Have a look at input file with particular instruments details which we use for query construction. Note that the file has Matlab syntax. About a year ago I made this project in Matlab, so I’m using some stuff arranged before. Step through the following script and fill the symbol table.
### Populating symbol_table
## Input file parse
out <- readLines("data/symbols.txt")
out1 <- gsub("[;'{}]", "", out[out != ""], fixed = FALSE)
out2 <- strsplit(out1," = ")
## Char to list
l <- vector("list",length(out2)/7)
rl <- 0
for (r in seq(1, length(out2), 7)) {
cl <- 1
rl <- rl+1
for (c in seq(r, r+6, 1)) {
l[[rl]][cl] <- out2[[c]][2]
cl <- cl+1
}
}
## List to dataframe
df <- do.call(rbind.data.frame, l)
colnames(df) <- c(
"symbol",
"months",
"exchange",
"name",
"product_group",
"currency",
"born_year")
df <- data.frame(lapply(df, as.character), stringsAsFactors = FALSE)
## Generating INSERT INTO query
source("qGen.R")
source("twodigityears.R")
q <- apply(df, 1, qGen, fromYear = 1980, toYear = 2060) # set desired time frame
q1 <- unlist(q, recursive = FALSE)
q1[[length(q1)]] <- gsub(",$", ";", q1[[length(q1)]])
q2 <- c("INSERT INTO symbol (exchange_abbrev, instrument, name, product_group, currency,created, modified) VALUES", q1)
q3 <- paste(q2, collapse = "\n")
# write(q3,"q2Output.txt") # uncomment just for debugging purposes
dbExecute(con, q3)
# Disconnect from database
dbDisconnect(con)
CME data parse
With tables with foreign keys for main table – daily_price, we can finally download, parse and export data to the database. Use my Parser R6 class. If you are interested in Parser implementation check readme file in the repository.
### Parser script
setwd("/Users/jvr23/Documents/R/CME_Parser")
source("Parser.R")
# Initialization of new R6 Class object
p <- Parser$new()
# Configuring database connection
p$set("db", list("192.168.88.202", 5432, "cauneasi54Ahoj"))
# parse method of Parser object downloads and parse settlement report files
p$parse()
# exportQuery method constructs SQL query and exports data to the database
p$exportQuery()
# Uncomment when running from CRON or other scheduler
q("no")
Let’s quickly check our new fresh exported data.
dbGetQuery(con, "SELECT * FROM daily_price ORDER BY complete_symbol LIMIT 30;")
Output should look something like this (created and modified columns are not shown).

Scheduling parserScript
Settlement prices are posted at approximately 6:00 p.m. CT which is around 23:00 UTC. That means that we could schedule parserScript.r to be executed every day at 23:11 UTC say with cron tool. Before we do so we need to create and configure .Rprofile to load needed libraries every time r is started.
$ cd $ nano .Rprofile
Paste following lines into the file and save (ctrl+o, enter, ctrl+x).
.First <- function(){
library("RPostgreSQL")
library("data.table")
library("DBI")
library("R6")
library("stringr")
}
.Last <- function(){
}
Test parserScript.r execution. (Every time you test run p$parse() and p$exportQuery() make sure you truncate daily_price table and change date in log/reportdate.log !)
$ r -f /Full/Path/to/CME_Parser/parserScript.R
R version 3.3.2 (2016-10-31) -- "Sincere Pumpkin Patch"
.
.
.
Loading required package: DBI
> ### Parser script
.
.
.
> p$parse()
Downloading data:.... OK
Loading settlement files:..... OK
Checking settlement reports date:... OK
Generating symbols for download:.......... OK
Generating SQL query rows:...... OK
> # exportQuery method constructs SQL query and exports data to the database
> p$exportQuery()
[1] TRUE
> # Uncomment when running from CRON
> q("no")
If execution was successful we can add entry to crontab.
$ crontab -e
Add following line.
11 23 * * 1,2,3,4,5 /full/path/to/r -f /Full/Path/to/CME_Parser/parserScript.R > /dev/null 2>&1
Congratulations! You have open-source home database solution for daily market data.